用于人体免疫分析的自动化管道
本案例研究说明了用于人体免疫分析的自动流式细胞仪分析管道的实际实施。
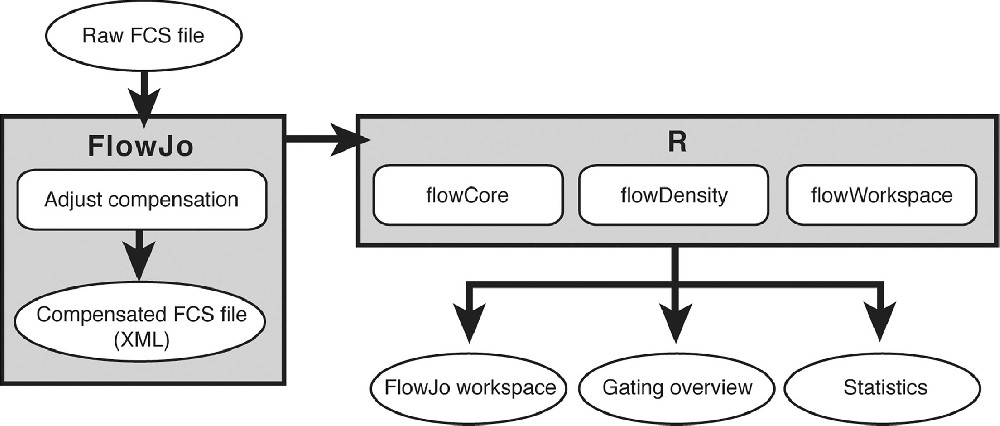
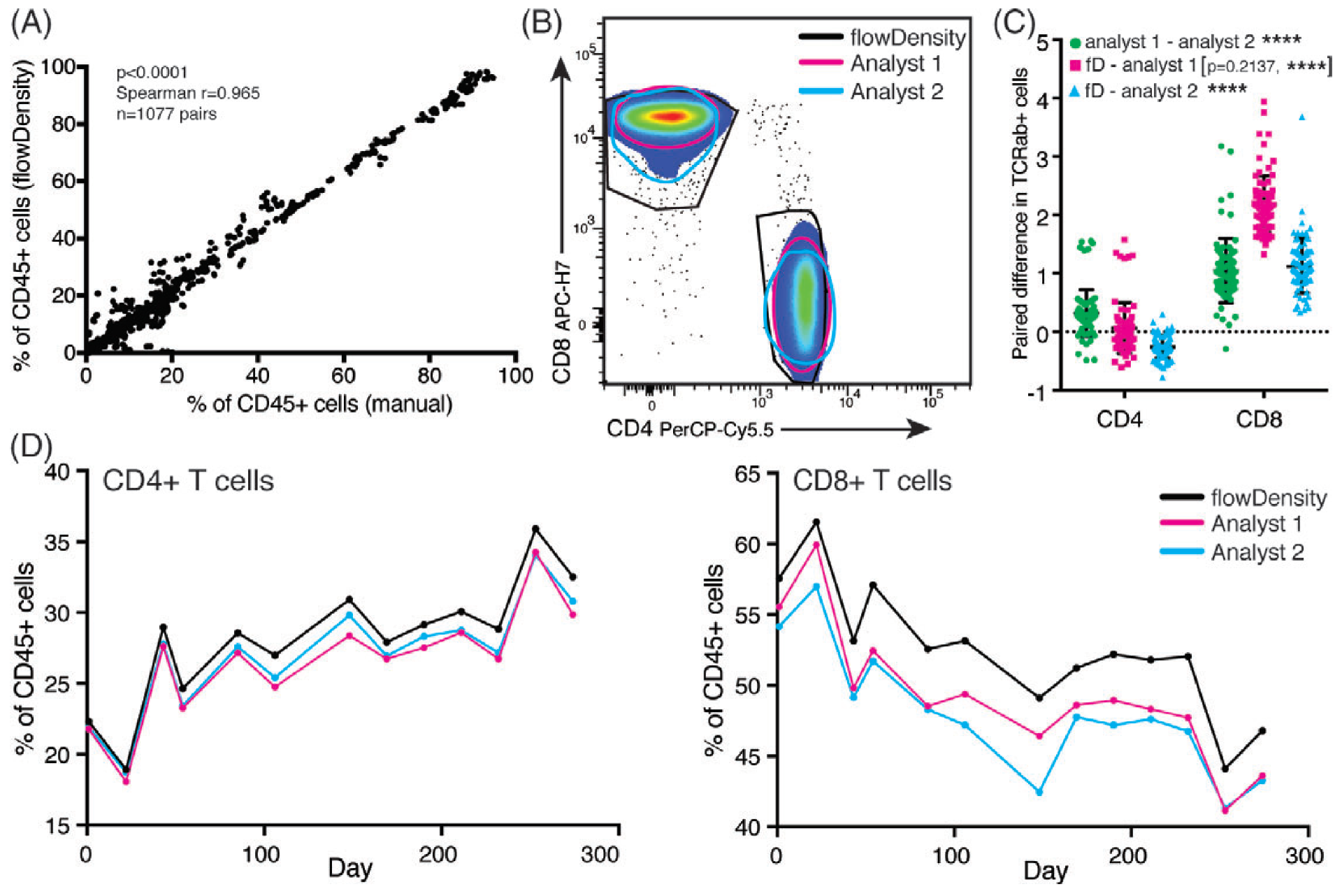
使用识别效应和记忆或辅助和调节 T 细胞的两个染色组生成数据。根据所需的分析深度,使用 8-10 种荧光染料的核心组来识别感兴趣的免疫子集,可以向其中添加三种荧光染料以测量每个患者每个时间点的 6-15 个激活标记。采集后,使用 FlowJo 软件打开 FCS 文件以调整补偿,并将生成的工作空间读入 R 以进行所有进一步的数据处理。虽然已经正确地将重点放在自动门控上,但一旦数据进入计算流,采用自动化方法进行细胞群识别开辟了额外的途径,以提高分析管道内临床试验数据分析的严谨性和可重复性。在使用此类方法完成预浇口质量检查后,然后通过 flowDensity 设置浇口。与倾向于通过同时检查所有维度来识别群体的典型聚类算法不同,flowDensity 基于顺序双变量门控方法,该方法使用为每个感兴趣的细胞群体定制的预先指定的方法生成一组预定义的细胞群体。该算法模拟手动门控步骤,但使用其密度分布的特征(例如密度斜率或密度的两个峰值之间的谷值)为各个标记选择最佳截止值。对于激活标记门控,将设置在荧光上的门边界减去一个对照用于匹配存在荧光染料的样品。根据这些规则为每个数据文件独立设置门。一旦门控步骤的参数化完成,门控步骤由单个脚本按顺序运行,只需要手动输入来指定文件所在的目录和输出的所需位置。只要新数据文件通常与用于设置门边界的数据文件相似,该方法往往是稳健的。然后,本研究测试了具有 flowDensity 的分析管道与领域专家对来自五名患者的数据进行的手动门控相比的执行情况。在总共 33 个时间点(每个时间点 2-4 次测试)上对相同的 11 个感兴趣的人群进行手动和自动分析,产生 1,077 个匹配的人群。这些群体的比较显示了 T 细胞面板的手动和自动分析之间的显着相关性(见下文)。虽然大部分人口表现出强烈的一致性,但通过自动分析对事件很少的人口进行手动门控并没有那么紧密地匹配。较大的分歧主要归因于该群体中的少量事件(门位置的微小变化对较小的细胞群体的影响被放大),其次是群体之间缺乏分辨率(即涂片)。当控制不用于此类稀有人群时,通常没有客观信息可用于指导自动化或门控。这使得对此类细胞群的自动分析方法的评估尤其具有挑战性。尽管存在这些差异,
上一篇:多中心生物标志物研究
下一篇:没有了!

 售前咨询专员
售前咨询专员
